Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


GPU support in Kubernetes helps us in intensive computing tasks like training machine learning models or handling big data. As more and more organizations start running their AI and ML workloads on Kubernetes, getting GPUs to work smoothly within Kubernetes clusters becomes critical.
GPUs are powerful, but they are also pricey and hard to get. If your Kubernetes cluster doesn’t use them efficiently, you risk either leaving them idle (wasting money) or overloading them, which hurts application performance. Kubernetes helps out by letting you manage GPUs as resources, just like CPU or memory, through device plugins that make the setup easier.
Managing GPUs in Kubernetes is all about keeping them consistently busy (without being overloaded) and available to the applications that need them most. Here are some best practices for managing GPUs effectively; let's discuss:
Kubernetes clusters can contain nodes with different types of GPUs (e.g., NVIDIA A100, V100, or Intel Flex GPUs) and your workloads may require a specific type of GPU for optimal performance. You can use the node labels to help the k8s scheduler match pods with specific GPU requirements to appropriate nodes. Without labeling, the scheduler might place workloads on inappropriate nodes, leading jobs to perform poorly or fail altogether.You can either manually label the nodes or use the Node Feature Discovery (NFD) plugin to simplify the process by automatically detecting and labeling nodes based on their hardware. Then we can reference these labels in pod specifications. It helps us make sure that the workloads land on nodes with the necessary hardware capabilities.
In Kubernetes, CPUs, and memory resources involve setting both requests and limits. With Kubernetes GPU, however, you can only define them in the limits section, meaning you cannot request a GPU without setting a limit. This ensures that each pod requesting a GPU has dedicated access to it. Unlike CPUs or memory, GPUs are generally scarce in clusters. So, always set resource requests thoughtfully, requesting only the GPUs your workload will actually use.
Requesting a single Kubernetes GPU in a pod’s specification:
>> Take a look at Guide to Resource Requests and Limits.
There are so many workloads in a cluster that do not require the full power of Kubernetes GPU, like certain inference jobs or media transcoding tasks. By enabling fractional resource management, you can allow multiple lightweight workloads to share a single GPU resulting in maximizing utilization.
The NVIDIA and Intel GPU device plugins both support mechanisms that allow a single GPU to be shared across multiple containers. Intel’s fractional resource management lets you specify GPU usage in millicores, enabling more granular allocation. You can also use time-slicing, MIG, or other concurrency options, which help partition a single physical Kubernetes GPU into isolated instances.
Configuring Fractional Resource Management (Intel GPU Plugin):
With the help of setting Node affinity, you can place GPU workloads on specific nodes that meet certain hardware requirements. This is useful in clusters where we have different types of GPU. Without setting node affinity, workloads could be scheduled on nodes with insufficient Kubernetes GPU resources, leading to bad performance.
Here’s a pod spec that requires a node with at least 40GB of installed GPU memory:
>> Learn more about how Kubernetes Scheduling Works?
You should consider different scheduling strategies for different workloads. For example, for time-sensitive jobs or high-performance applications, use node selectors and affinity rules to pin them to high-end GPU nodes. For non-critical jobs, schedule them on older or less powerful GPUs to save costs. If you don’t customize the scheduling, high-value workloads might get stuck on underpowered GPUs.
>> Take a look at PerfectScale by DoiT Unveils GPU Support and Node-Level Optimization
GPU health monitoring is important for maintaining uptime and performance in production environments. If a GPU overheats or encounters a memory issue, it could lead to job failures or even hardware damage. Health monitoring detects these issues early.
You can use the health management features provided by GPU plugins, such as NVIDIA’s DCGM or Intel’s Level Zero API, to track GPU metrics like temperature, memory usage, and utilization. Set up alerts to notify you of potential issues before they impact applications. Without health monitoring, you risk undetected GPU failures causing downtime or data loss. This is important for clusters running high-availability applications where downtime needs to be minimized.

You can set up RBAC Policies to restrict GPU access to workloads and users that only require it. With RBAC, you can control access to specific resources and namespaces within your Kubernetes cluster, preventing unauthorized use of GPU resources.
Example: Restricting GPU Access to Specific Users
Suppose you have a user named tania who needs access to GPU resources within the ml-project namespace. You can create a Role that grants permissions to use GPUs and then bind this role to the tania user.
Define a Role with GPU Access Permissions:
This role allows the creation and management of pods and jobs, which can be configured to request GPU resources.
Create a RoleBinding to associate the Role with the User:
This binding associates the gpu-access-role with the tania user in the ml-project namespace.
By setting up RBAC policies in this manner, you ensure that only specified users can deploy workloads that utilize GPU resources, enhancing the security and proper utilization of your cluster's GPUs.
You can use DRA which can enhance GPU efficiency by dynamically allocating resources based on workload demands. For example, NVIDIA’s DRA, allows GPUs to be dynamically assigned and released, enabling more responsive scaling. DRA prevents resource contention by ensuring that GPUs are allocated precisely when needed, maximizing utilization without under or over-provisioning.
Note: This DRA resource driver is currently under active development(is in beta stage) and not yet designed for production use. It requires further maturation before it can be reliably implemented in production clusters.

The right approach to GPU resource management helps keep GPU workloads running smoothly, optimizes costs, and prevents performance issues. Kubernetes allows you to treat GPUs as first-class resources, but it’s up to you to make the best use of that capability by aligning GPU deployment and usage with your applications' exact needs. By following the above best practices, you ensure efficient GPU utilization and scalable and reliable clusters.
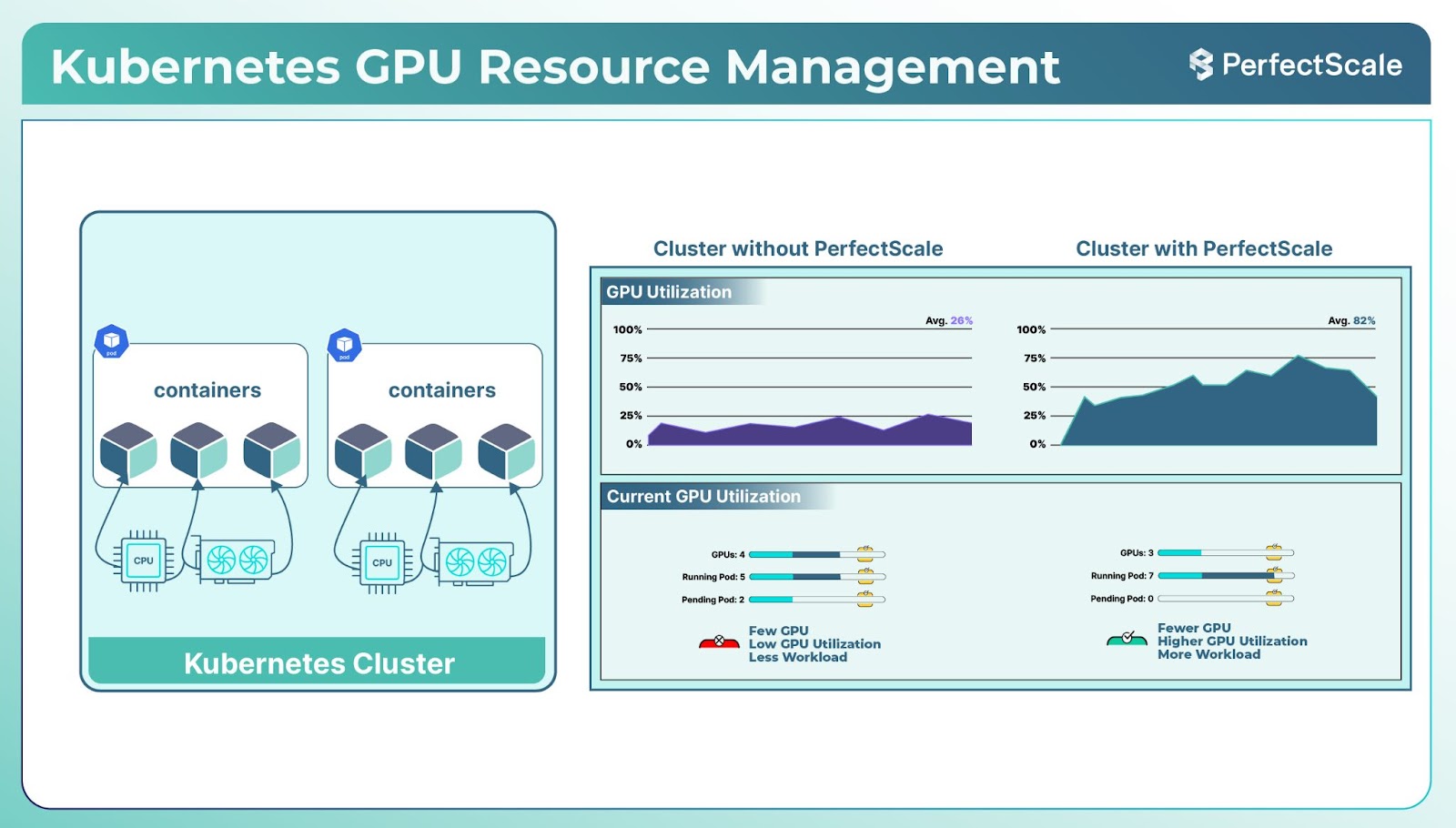
PerfectScale by DoiT enhances Kubernetes GPU management with powerful new features for real-time visibility and advanced node-level optimization. These capabilities empower teams to maximize GPU efficiency while cutting costs, making PerfectScale by DoiT a key tool for managing AI, ML, and HPC workloads in Kubernetes.
1. Real-Time Visibility: Monitor GPU utilization per workload, identify inefficiencies, and adjust proactively.
2. Cost-Saving Recommendations: Unlock up to 50% additional savings by optimizing idle and misaligned GPU resources.
3. Automated Optimization: Future features will enable autonomous GPU allocation adjustments for seamless performance tuning.
4. Node-Level Insights: InfraFit recommendations ensure optimal GPU and node configurations to streamline usage and costs.
5. Early Access Opportunity: Join the waitlist to be among the first to benefit from these advanced GPU management capabilities.
With Kubernetes GPUs accounting for up to 75% of cloud costs in AI-driven environments, PerfectScale by DoiT ensures that your Kubernetes clusters are efficient, scalable, and cost-effective. By integrating seamlessly with tools like Karpenter and ClusterAutoscaler, PerfectScale by DoiT transforms GPU resource management into a streamlined, data-driven process. Unlock smarter GPU management with PerfectScale by DoiT. Sign up, Book a demo, or join the waitlist for early access to GPU optimization. Optimize Kubernetes with PerfectScale by DoiT and make every GPU dollar count!


Install in minutes and instantly receive actionable intelligence.

.png)




.png)

.png)