GPU Optimization
for Your AI and LLM-Based Applications
Reduce K8s costs and maximize AI services efficiency with exceptional real-time GPU allocation and utilization visibility.

Drive Innovation, Not Your Cloud Bill: Keep GPUs in Check
PerfectScale by DoiT continuously monitors your clusters and uncovers GPU optimization opportunities, helping you significantly reduce cloud spend.
Granular GPU Utilization Visibility
Get comprehensive insights into GPU utilization across clusters and node groups to identify usage patterns and trends over time.

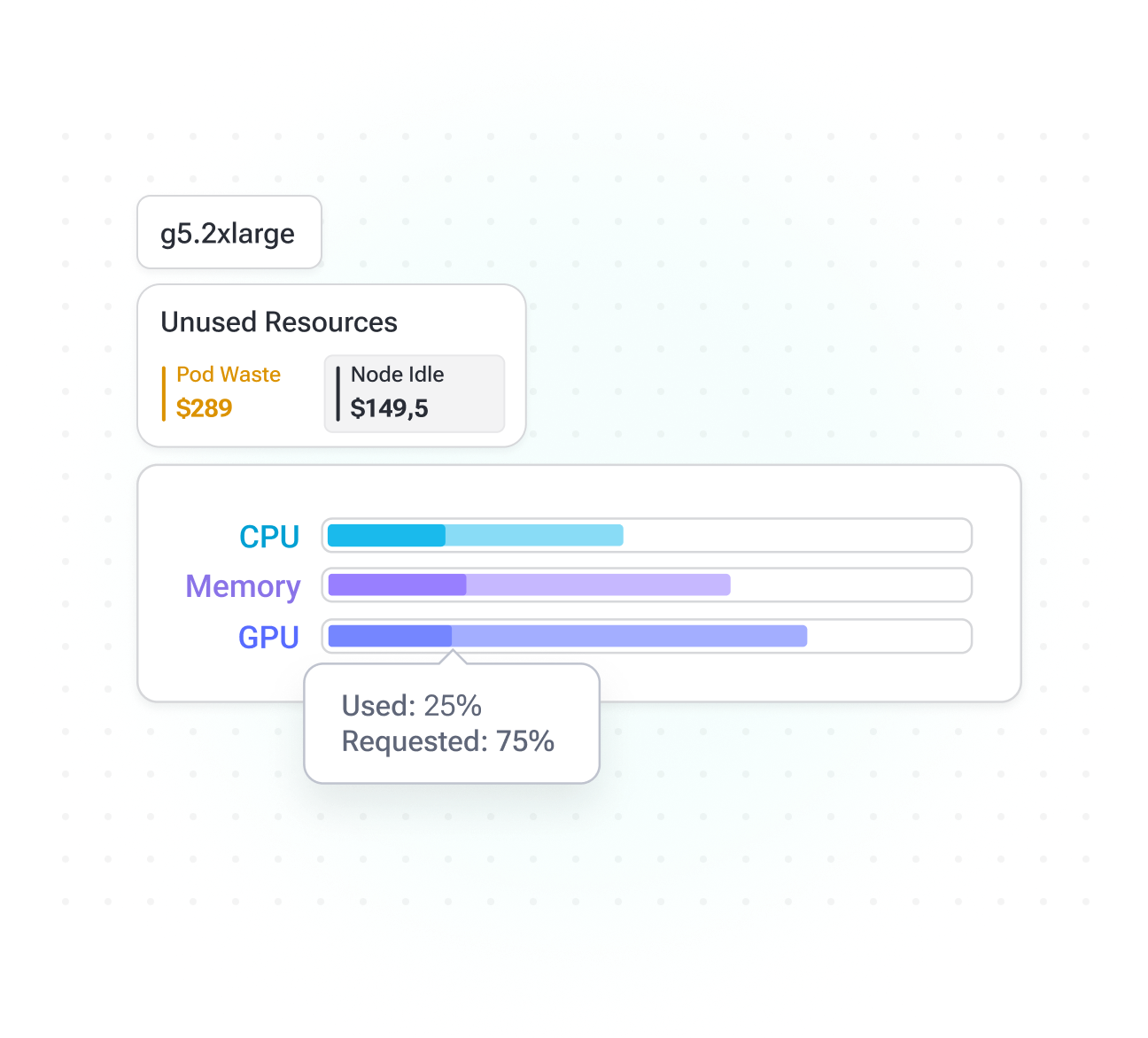
Instant GPU Waste Detection
Seamlessly identify inefficiencies across your AI infrastructure by pinpointing idle, underutilized, or misconfigured nodes to prevent unnecessary costs and scaling events.
Lean GPU Infrastructure
Right-size workloads running on GPU nodes using data-driven recommendations or automation to improve scheduling and remove unnecessary, costly nodes.

Install in minutes and instantly receive actionable intelligence.
FAQs
Yes, PerfectScale’s Community Package is free for life. Premium features, like automation, are available for Community users for the first 30 days after creating an account. Sign up here.
Kubernetes GPU optimization is a complex process to align GPU resource allocation with actual workload demand to eliminate waste, improve utilization efficiency, and reduce K8s cloud spend. It ensures the workloads have the exact number of GPUs to perform well without jeopardizing performance.
To reduce GPU costs in Kubernetes, you need accurate visibility into real-time GPU utilization, workload behavior patterns over time, as well as node-level visibility to evaluate bin packing efficiency, identify idle capacity, and convert it into optimization opportunities. By rightsizing GPU workloads according to demand, improving bin packing, and selecting the most cost-efficient GPU instances, you can seamlessly reduce cloud spend while maintaining the performance and stability of AI services.